
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- VS Code 오류
- 풀이
- AWS Cloud
- FSB
- Dreamhack.io
- Android
- pandas
- ubuntu
- 클라우드
- 빅데이터 분석기사
- [EduAtoZ]
- 빅데이터 분석기사 실기
- 워게임
- AWS
- error
- 보안뉴스
- 빅데이터분석기사
- dreamhack
- 인프런
- centos7
- ios frida
- tcache
- Python
- nmcli
- pwnable
- wireshark
- 빅데이터분석기사 실기
- Linux
- 빅분기 실기
- mariadb
- Today
- Total
0netw0m1ra
[053] 빅분기실기) 작업형2 예시 문제 실습 본문
<문제>
https://www.dataq.or.kr/www/board/view.do -> 응시환경 체험 3번 문제
<해결>
1. 문제 이해
고객 3,500명에 대한 학습용 데이터(X_train.csv, y_train.csv)를 이용하여 성별예측 모형을 만든 후, 이를 평가용 데이터(X_test.csv)에 적용하여 얻은 2,482명 고객의 성별 예측값(남자일 확률)을 다음과 같은 형식의 csv 파일로 생성하시오.
- X_train.csv : 3,500명 데이터, 고객의 상품구매 속성(학습용)
- X_test.csv : 2,482명 데이터, 고객의 상품구매 속성(평가용)
- y_train.csv : 고객의 성별 데이터(학습용)
2. 파일 읽어오기

3. 전처리
1) 데이터 확인
2) 결측치 제거 / 대체
# 많은 양의 결측치가 있으므로 '환불금액' 결측치를 사용하지 않는 방법
# 다른 값으로 채우기 - 범주형(새로운 범주 생성), 연속형(평균, 중앙값)
# 상관관계가 높은 값이 있다면 제거해야 함 : -1또는 1에 가까운 것은 좋지 않음
# 현재 문제에서는 해당없음
# 하지만, 0.9 이런 식으로 1에 가까운 값이 있다면 제거하는 것이 좋음
* df.loc[:3500, :] -> 3500을 포함하기 때문에 3501개
* df.iloc[:3500, :] -> 3500을 포함하지 않기 때문에 3500개
3) dtype : object -> 숫자형으로 적절한 변환 필요
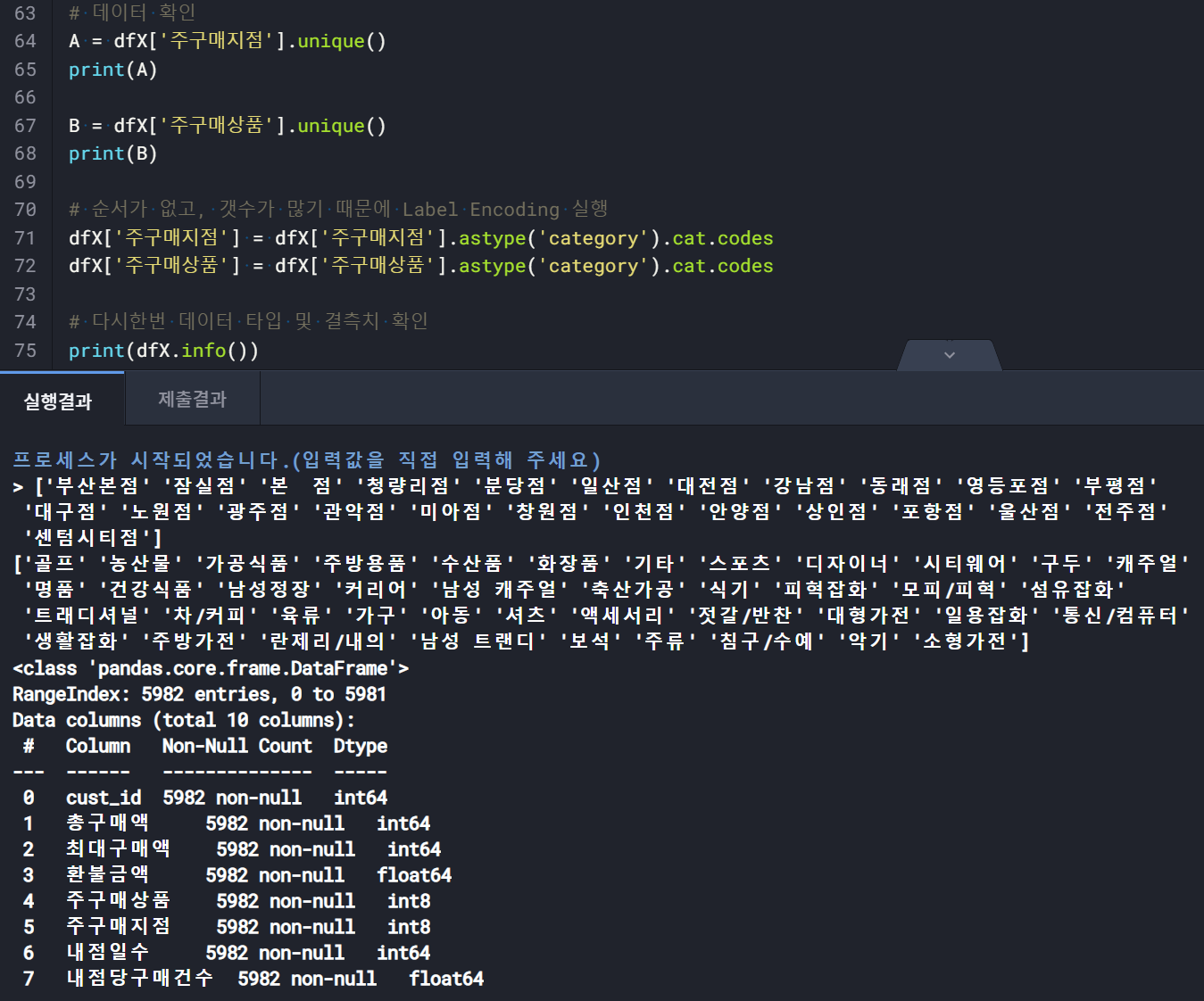
4. 데이터 모델링
1) 라이브러리 import

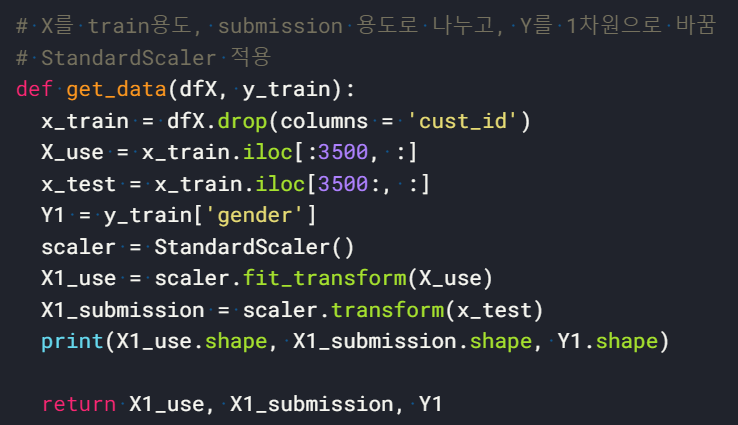
2) X, Y 분리하기 : get_data()
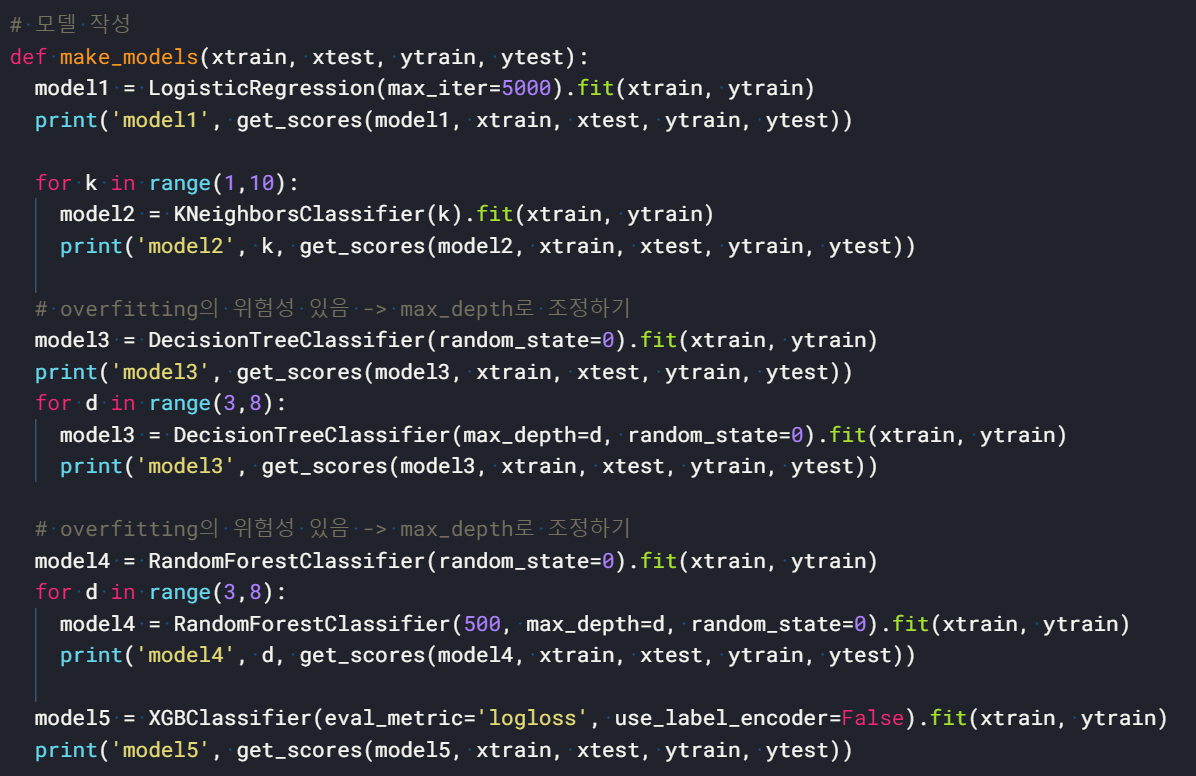
3) 모델 만들기 : make_models()
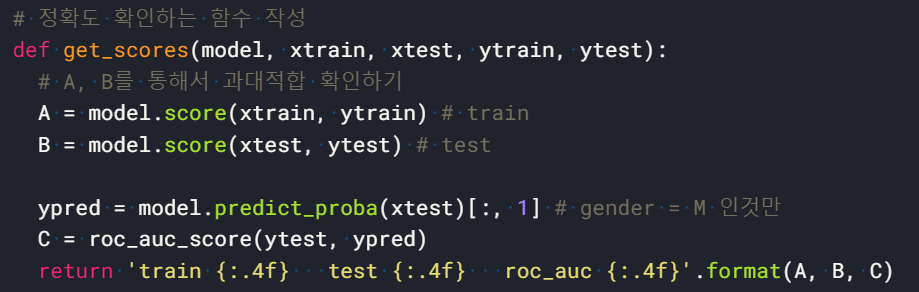
4) 모델 성능 확인 함수
5) 가장 높은 정확도 가진 모델 찾기 -> model4
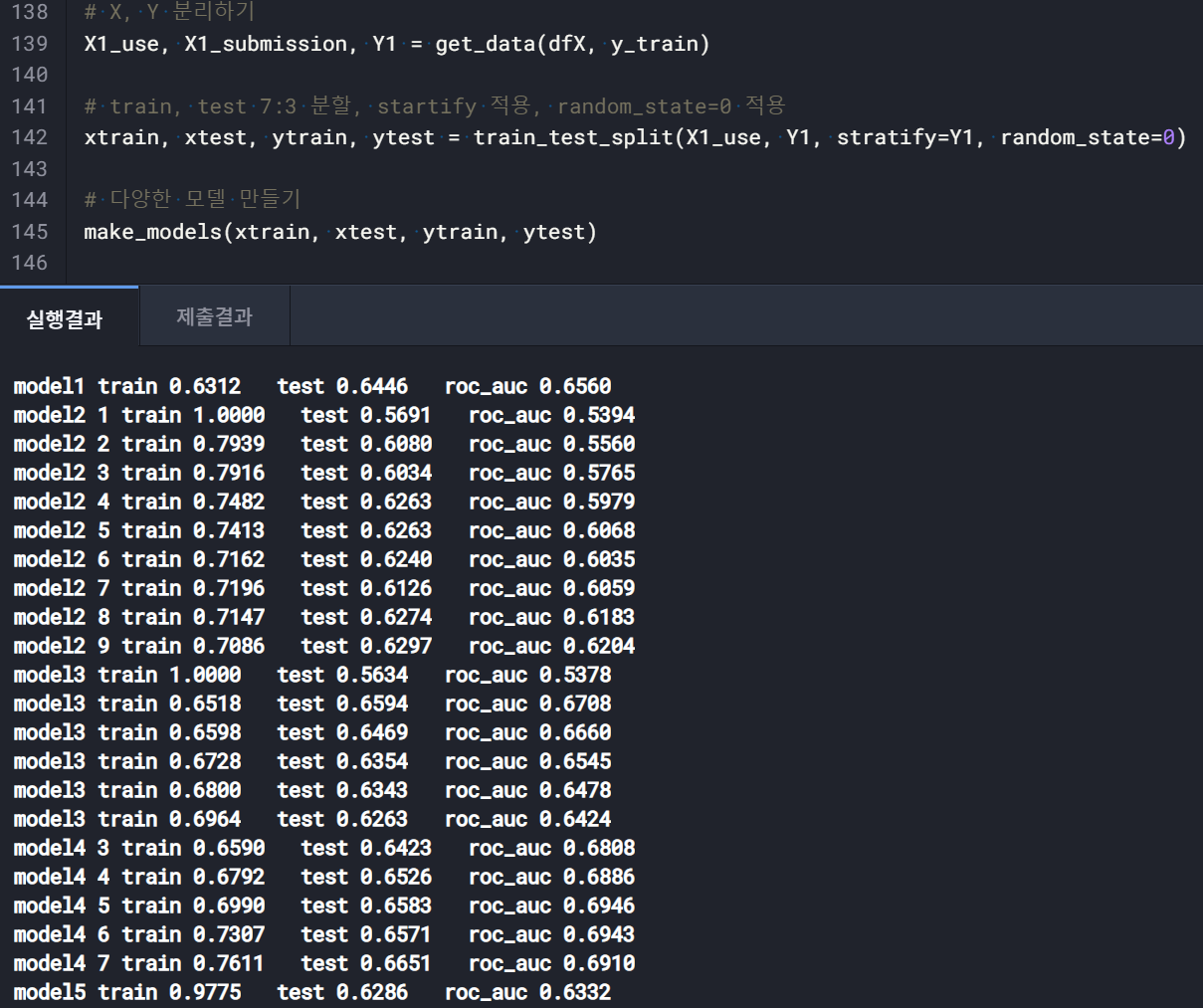
6) 모델 선택

5. 최종 제출


<출처>
인프런 - [EduAtoZ] 빅데이터분석기사 실기 대비 Part3. 고객의 성별 예측 예시문제 풀이
'빅데이터분석기사 실기' 카테고리의 다른 글
| [054] 웹사이트 방문자 예측 실습 정리 (0) | 2022.06.24 |
|---|---|
| [052] 분류모델 - 오분류표, 확률 구하기, 예측값 저장 (0) | 2022.06.22 |
| [051] 분류모델 - LogisticRegression, KNeighborsClassifier, DecisionTreeClassifier, RandomForestClassifier, XGBClassifier (0) | 2022.06.22 |
| [050] 모델 학습 및 성능 평가 (0) | 2022.06.22 |
| [049] Machine Learning - 분류 모델 실습 (0) | 2022.06.22 |

